tts更换模型和训练
训练TTS(文本转语音)模型
(确保显卡显存至少有6G)
1.来到这个路径:my-neuro/tts-hub/GPT-SoVITS-Bundle
2.鼠标往下滑,找到“启动web.bat”文件,双击打开
4.打开后就来到了gpt sovits的训练web窗口 可以观看gpt sovits教程视频学习如何训练(B站上面有很多)
推理TTS模型
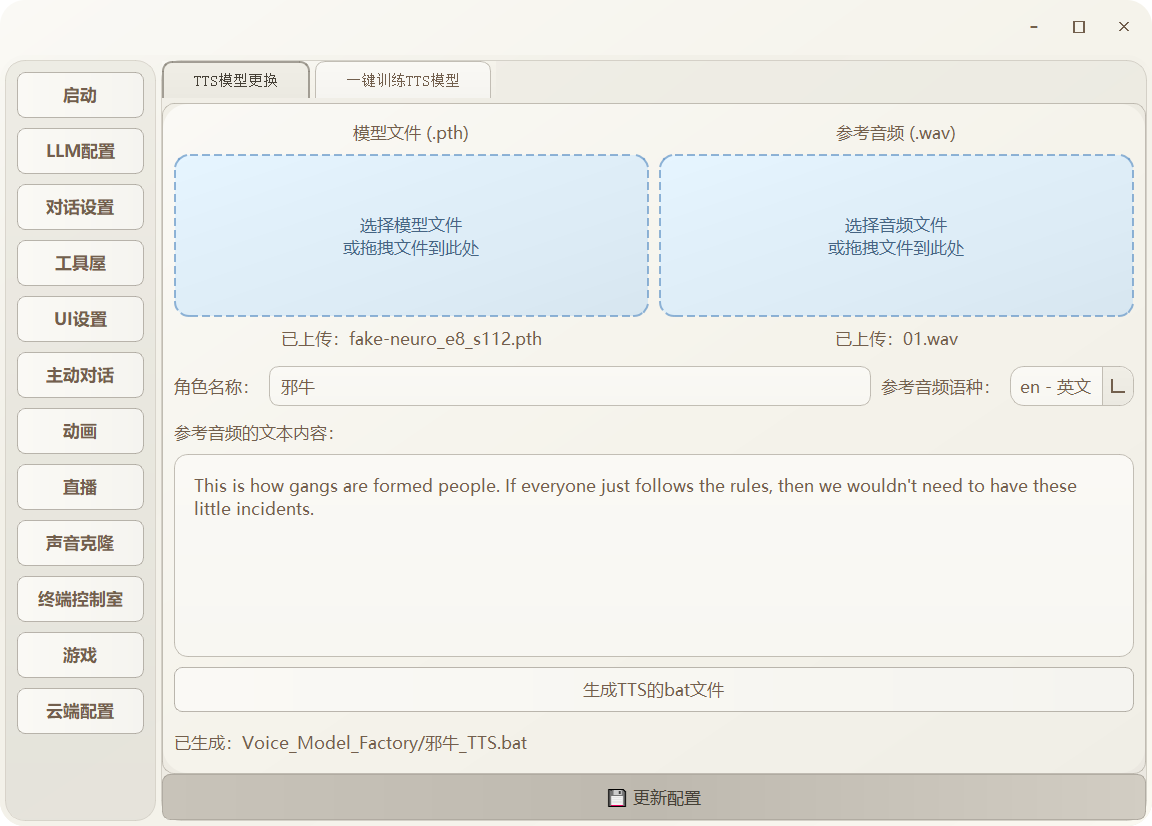
打开肥牛.exe
按照图中的顺序配置好你的音频模型
最后点击“生成TTS的bat文件。会在live-2d文件夹中的Voice_Model_Factory文件夹下生成你的bat格式的文件。只需要双击运行。你训练好的tts的服务即可启动
接下来就可以启动皮套。模型就会以训练后的声音和你对话了。
例子:我训练好了一个模型,按照要去将模型、音频内容、角色名字等都搞好了,最后点击“生成TTS的bat文件
然后去live-2d文件夹下,打开Voice_Model_Factory 文件夹
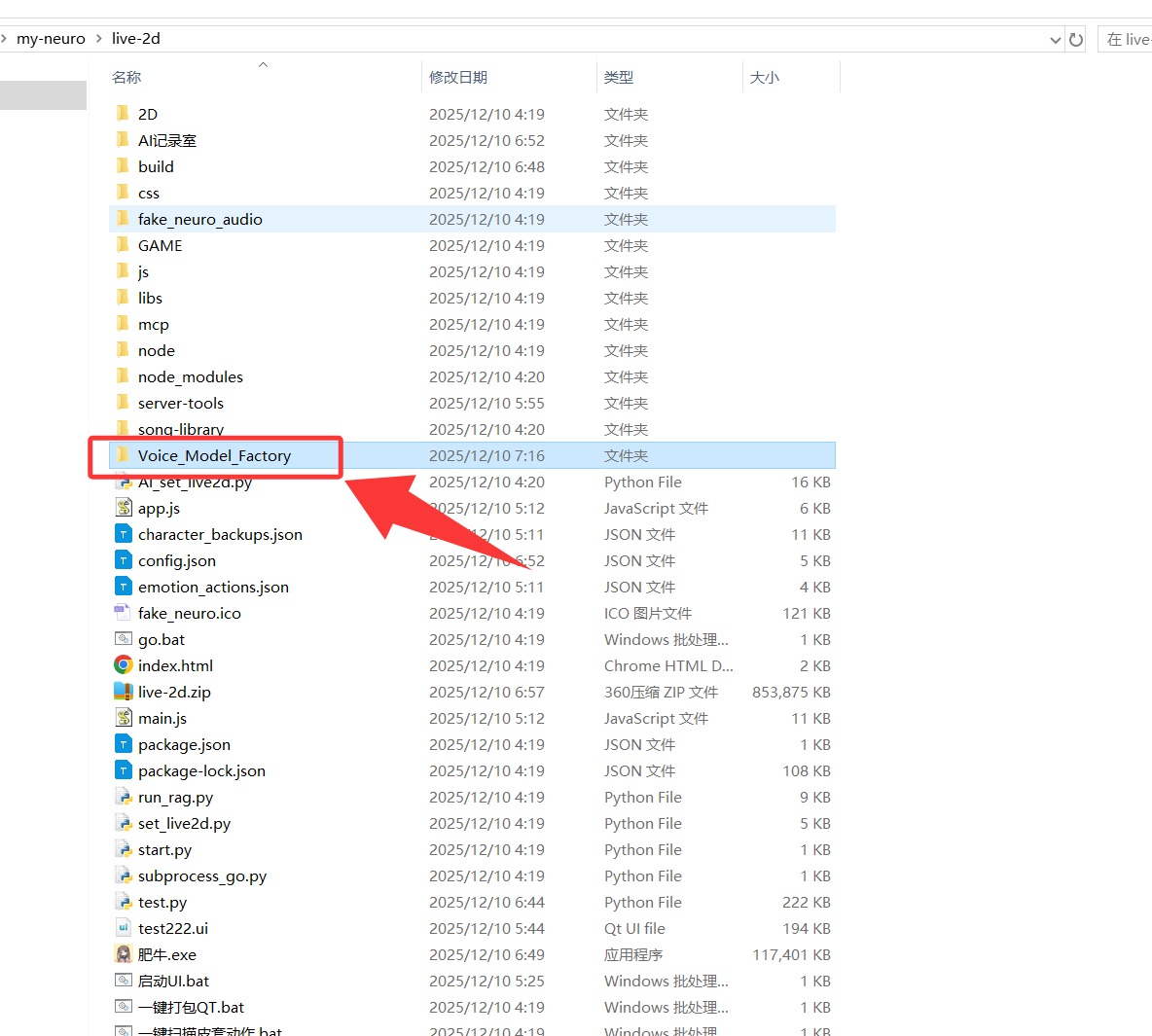
里面就会生成一个bat文件,这就是全新tts启动文件。里面是你更换的角色,后续就可以不用去my-neuro目录下双击:TTS.bat 了
